

As some of you may recall, A few months ago, there was a lot of hoopla about an unofficial P.C. port of Super Mario 64. Fans had managed to decompile and reverse engineer the source code of Mario 64 and made the necessary changes to compile and run the game on Windows. So why is this such a big deal when we can already play N64 games using emulators? Conversely, what’s it matter that the games in the Super Mario 3D All-Stars Collection are emulated and not ported? What’s the difference between porting and emulating? And why would developers choose one over the other?
What is Emulation?
As always, let’s start with some definitions. An emulator is a program (i.e. software) that mimics the hardware a device or an operating system. A software port is a version of a program that runs on a different platform than the original program. Note that, in regards to games, a port is different from a remake in that a remake is—as the name implies—when the game is remade from the ground up, while a port uses the same assets and code with minimal changes.
Alright, so let’s break that down. An emulator basically acts as a middleman between the system it’s running on, known as the host, and the program it’s running. In a sense, an emulator is like an interpreter translating the instructions the program lists into a form the host understands. This means the emulated program is completely unchanged, hence why emulated games are often referred to as R.O.M.s (read-only memory).
An emulator basically acts as a middleman between the system it’s running on and the program it’s running.
Porting skips the middleman and just runs the program directly on the target platform. Unlike emulation, this almost always means having to adjust parts of the program. In the case of games, this often means down-scaling assets such as models or textures to run smoothly when porting to weaker hardware, and invariably means rewriting the parts of the game’s code, specifically those that interface with the console’s subsystems (such as accessing a save file in system storage) and hardware (such as the controller). The goal when porting is typically to produce a stable version of the program while having to change as little of the code as possible.
Why do Programs Need to be Ported?
All of this leads to the question of why any of this is even necessary. Why do old games need a middleman to run on modern hardware or to be partially rewritten? Why can’t the game’s R.O.M. just be loaded onto the system and run like any other program? After all, programs are ultimately all just ones and zeroes, right?
Well, as to be expected, it’s not that simple. It is true that all programs are, in fact, binary code; the operative term here being “code”. Binary sequences, commonly called “machine code”, are formatted in a very particular fashion so that the C.P.U. can interpret them as instructions, with different models of C.P.U. having their own rules for reading and executing machine code. The rules that a C.P.U. follows are collectively known as its “Instruction Set Architecture” (I.S.A.). If you’ve ever looked up the hardware specifications for Nintendo hardware, you’ve no doubt heard of some of the more famous I.S.A.s: MIPS, ARM, PowerPC, and so on.
Binary sequence are formatted in a very particular fashion so that the C.P.U. can interpret them as instructions, with different C.P.U.s having their own rules for doing so.
So what exactly does an I.S.A. define? In short, it outlines the most basic operations of the C.P.U., how they work, and how they’re represented in binary. An I.S.A. will include operations for arithmetic, memory management, and program control, among other operations. In addition, I.S.A.s also specify additional details such as how many registers are in the C.P.U. and what they’re used for, how data is transferred between R.A.M. and the cache, and even what order to read bytes in (for more information on what registers, the cache, and R.A.M. are, see this article). So, in short, an I.S.A. is basically a blueprint for a C.P.U., and to some extent, a computer as a whole.
While most C.P.U.s share a common set of operations, the way they go about implementing them can vary wildly. Let’s look at an example. Below is a visual representation of two implementations of same program for two fictional I.S.A.s: GKS-92 and TBC. GKS-92 uses an accumulator while TBC utilizes a load-store architecture (I’ll explain what those means in a moment). All the program does is simply load two values from two memory addresses—named “VAR_A” and “VAR_B”, respectively—add the values together, and write the sum to a third memory address named “VAR_OUT”.
It looks something like this:
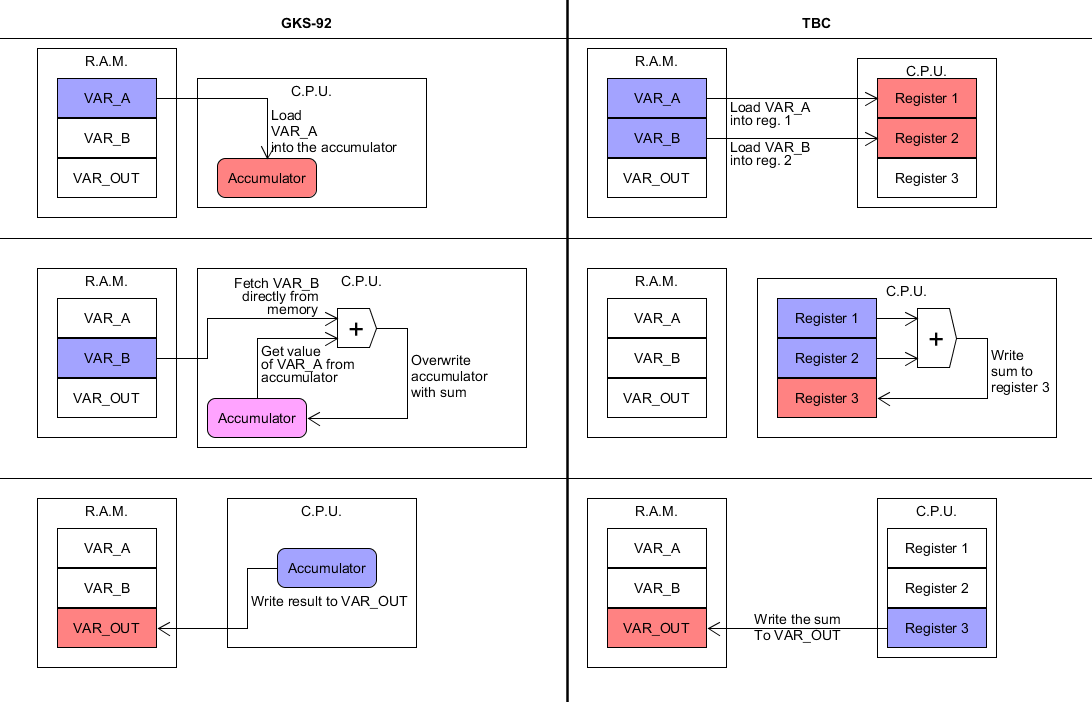
As you can see, despite effectively being the same program, the two implementations look very different. GKS-92 uses what’s called an accumulator, which means that the C.P.U. only has one general purpose register that directly accesses data from memory to operate on. Once it has a result, the register then overwrites itself with the result, thus the value “accumulates” overtime. TBC, as stated earlier, uses a load-store scheme, meaning it possesses multiple general-purpose registers, but it can’t operate on data directly from memory. As you can see from the diagram, it must first load the values from memory into registers one and two before any math can take place. Moreover, the values of the registers are unaffected unless they’re specifically designated to be written to, like register three is in step two of TBC’s execution
With how different the C.P.U.-level execution is for both of these, just imagine what it must look like in binary—or what it would if either of these were real architectures. Both machines perform even simple arithmetic completely differently, meaning any machine code for one would be unintelligible to the other.

Fortunately, this isn’t too much of an issue these days, as we now have high-level programming languages. These languages allow programmers to write code that’s not only much easier to read, but can then be translated by a program called a compiler into machine code. For instance, in the C programming language, the above code would look like:
var_out = var_a + var_b;
Much cleaner, and more importantly, it doesn’t have to be rewritten for each distribution platform; the compiler sorts out all of that nonsense for us!
Okay, so if we have high-level languages, then all we need to do to port a game is recompile the code with the right compiler, right? I’m sure it’s no surprise to you by now to hear that—once again—it’s not that simple. Even code written in a high-level language eventually has to interface with a console’s hardware, necessitating a means of bridging the gap between high-level code and a system’s low-level functions. This is where Application Programming Interfaces (A.P.I.s) come in.
An A.P.I. is a collection of tools used to aid programmers in making programs, typically in the form of prewritten code that handles some aspect of the program, such as the user interface, audio, or networking. A.P.I.s are especially useful in regards to interfacing with low-level features (input, graphics, file access, etc.), which would otherwise require each team to write their own low-level code, possibly in assembly.
As to be expected, every system has its own proprietary A.P.I.s that each do things a little differently. For this reason, code targeting one platform can’t be compiled to run on another. To use an example from my own programming misadventures, I’ve encountered instances where one controller A.P.I. maps the vertical position of joysticks so that pressing up sets the stick’s vertical position to a positive number, while another A.P.I. maps it to a negative one. All of these issues, and undoubtedly many more, have to be addressed when porting a game from one system to another.
Emulation vs. Porting
Okay, so porting can be a lot of work. Does that mean emulation is the better option? Well, seeing as we frequently use both, the answer unsurprisingly is: it depends. Emulators are complicated things to make, requiring a deep understanding of the inner workings of the system they’re meant to emulate. If done right, however, one program could in theory run hundreds of others, greatly reducing the amount of work it would require to make a company’s back-catalog available on modern hardware.
There are limitations, however. Emulation is not a lightweight operation by any means, requiring a lot of additional processing power and memory in comparison to the original game. This is why developers have to port games to run on multiple systems of the same generation: the overhead of emulating a game far exceeds the resources available on contemporary consoles. Likewise, it’s also why games from one or two generations ago are typically ported instead of emulated. Even with the significantly more powerful hardware we have available to us, running last generation’s games smoothly via emulation isn’t possible on today’s consoles.
Emulation is not a lightweight operation by any means, requiring a lot of additional processing power and memory in comparison to the original game.
Moreover, some system features are difficult to emulate due to differences in how the host machine and the emulated platform are built. For instance,Super Nintendo games could have unique chips built into the cartridge (such as the Super FX Chip) that add an extra layer of complexity for emulators. The N64 featured a Unified Memory Architecture (U.M.A.) meaning that the C.P.U. and the graphics processor shared memory. Modern computers and consoles use separate memory for the C.P.U. and the G.P.U., meaning some graphical effects on the N64 are tricky—though not impossible—to emulate on modern hardware due to this separation of memory. A classic example is using the current frame of gameplay as a texture for an object, such as the screen in Luigi’s Raceway from Mario Kart 64.
So to reiterate, porting has to be done for each individual game but requires less computing power, while emulators are imprecise but can be used for multiple games, thus saving time in the long run.
Seeing Super Mario 64 run natively on P.C. is a curiosity I didn’t know I wanted. As per usual, Nintendo wasn’t too thrilled about it and C&D’d it just like Another Metroid 2 Remake. Thankfully, with the 35th anniversary of the Super Mario franchise this year, Nintendo is releasing emulated versions of many of Mario’s best adventures, including Super Mario 64. And hopefully, you now understand what that means and why a developer would choose one over the other.
If you have any further questions, feel free to leave a comment below. Likewise, if there’s anything you’d like explained about how video games work, let me know in the comments or shoot me an email at Glen@TwoButtonCrew.com and I just might write an article explaining it.
Glen
Latest posts by Glen (see all)
- Sigma Star Saga That Was a Thing - 05/10/2026
- Goodbye, Two Button Crew - 12/28/2023
- TBC 40: The Legend of Zelda: Tears of the Kingdom - 12/27/2023
